
SLAI新突破!快速规模化适配 + 端到端提速
深圳河套学院联合智子芯元、昇腾AI、深圳市大数据研究院通过Agent驱动的一体化流水线,实现模型迁移百倍效率提升、性能精准优化,为国产算力的多行业规模化应用按下“加速键”。
当前国产算力正进入规模化落地阶段,面对多行业、多任务的应用场景,一个关键挑战是:
全球前沿模型能否在国产AI芯片上实现快速配置、高效运行?
在国产算力上,模型迁移通常需要跨过两道关:
1)让模型快速跑起来:兼容硬件环境、Pytorch模型、国产芯片已有算子等;
2)让模型跑得更快:定位推理链路中的瓶颈,并进行系统性优化。
传统流程往往依赖人工经验与反复试错,难以支撑多模型版本、持续迭代的交付节奏。为此,我们将“规模化适配 + 端到端优化”贯通为一条可复现、可验证的交付链路,把迁移从经验驱动的试错过程,转为可复制的工程流程。目前工作重点面向昇腾平台展开,同时,核心流程也已在其他国产芯片平台上完成初步可行性验证。

从“一次能跑”到“长期可交付、可提速”
01
简介:
从“适配靠经验”到“交付靠系统”
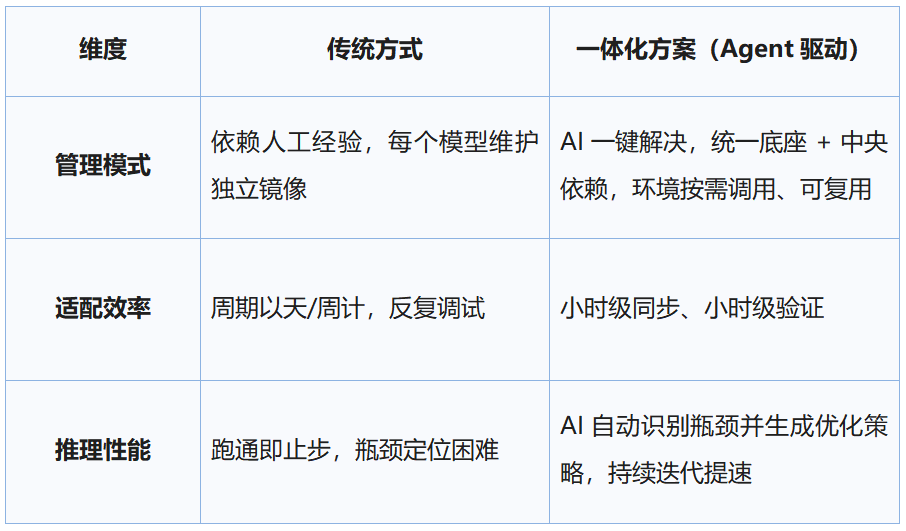
传统跨平台迁移往往呈现两类典型痛点:
• 环境碎片化:每个模型维护一套镜像,依赖冲突频发,迁移全靠手工试错。
• 性能不可控:即使“能跑”,端到端吞吐常被预处理、解码循环、算子选择等因素隐性瓶颈拖慢。
我们用Agent化的一体化方案把“适配—优化”串成一条链路。两个方案的对比如下:
02
国产算力上的规模化模型适配
我们将复杂的硬件适配经验固化为可执行的智能体Skill工作流模块(注:SKill工作流指的是让AI学会执行某项具体任务的专门能力或“技术指南”)。这套面向AI智能体的“工程指南 + 工具集”,使智能体能够自动识别 NPU 驱动并通过多次试错中的经验,自主完成环境同步任务。交付效率与覆盖成果如下:
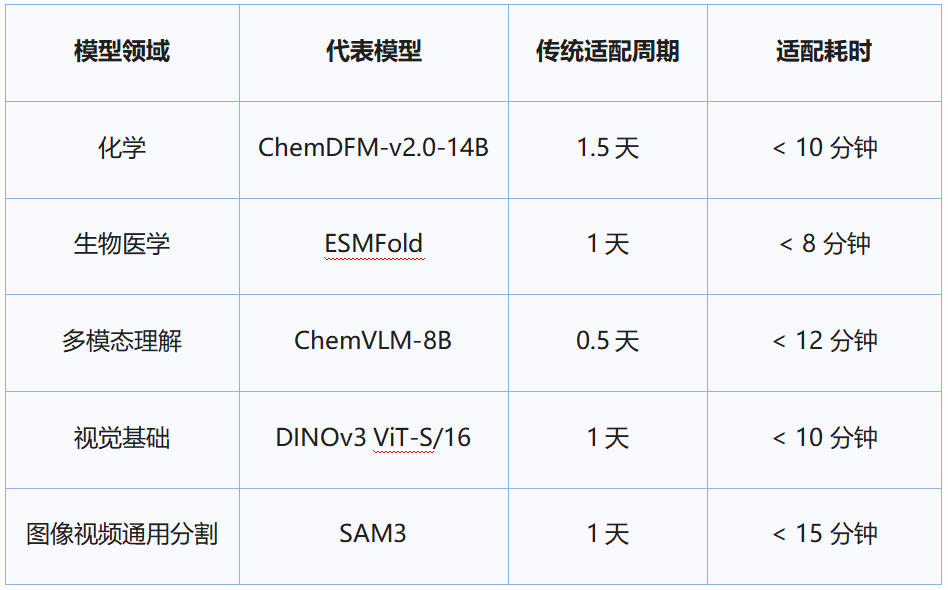
• 小时级极速适配:对一些主流模型,10 分钟内完成从环境配置到推理 Demo 运行;对绝大多数模型,1 小时内也可完成适配。
• 500+ 模型覆盖:我们采用“深度精修”与“规模自动化”结合,完成了对 ChemDFM、ESM2、DINOv3 等科学计算与前沿视觉标杆模型的深度适配;此外,依托多智能体协作机制,实现了 500+ 模型的自动适配。需注意,自动库侧重于规模化可行性验证,代码质量可能受模型复杂度影响存在波动,后续将结合 CI 机制进行长效自愈。
以下是部分主流模型的适配时间实测:
03
模型适配后的自动优化提速
在稳定运行模型后,下一个问题是:模型性能如何进一步提升?我们开发了一个更全面的智能体工具,可实现自动优化:以端到端视角自动定位性能瓶颈,并通过自定义解码循环、快速预处理管线等手段,自动生成并应用优化方案,实现性能提升。
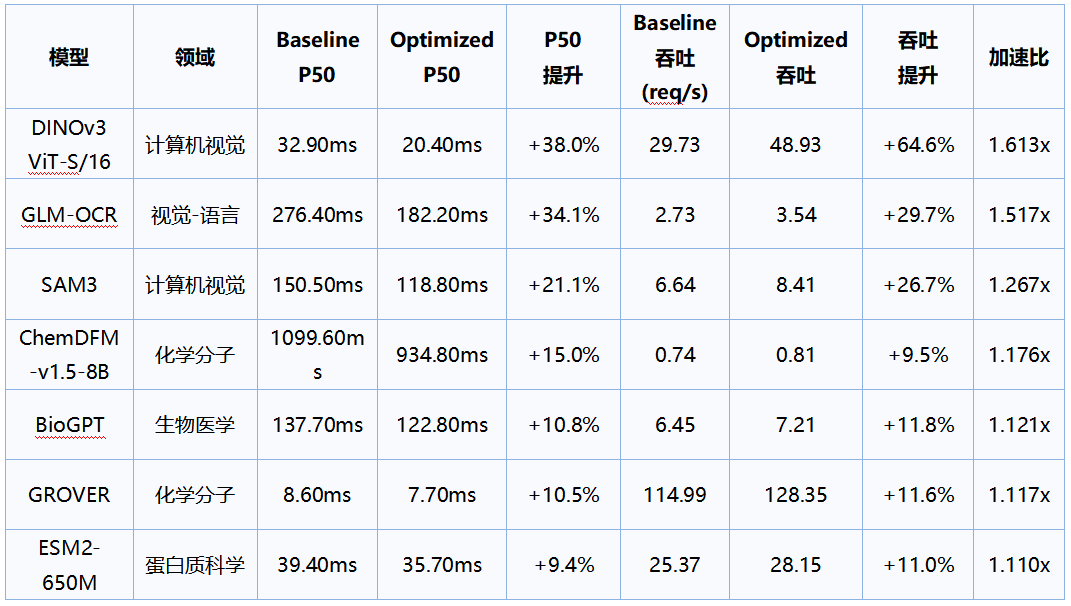
我们比较了初步适配过的模型和自动优化后的模型,在7个代表性模型上完成系统验证:系统响应时间(用P50延迟来衡量)平均降低18.4%,最高降低38.0%;模型吞吐平均提升 23.3%(最高 64.6%)。下文是详细的对比:
名词解释:延迟(latency)指一次请求从发起到返回结果的端到端耗时;“P50 延迟”为延迟分布的 50% 分位点(中位数),反映典型请求的响应时间。
推理提速效果对比
注:初步适配后的模型与自动优化后的版本对齐了预热策略、测试数据与参数配置。
在一些典型案例上,我们找到的自动加速方案和效果如下:
• DINOv3:轻量模型的真实瓶颈常在预处理。以自定义快速预处理管线替代通用 ImageProcessor,使端到端 P50 降低 38.0%,吞吐提升 64.6%。
• GLM-OCR:通过 NPU ACL 算子级优化与推理路径精简(避免不必要的 I/O),P50 降低 34.1%。
• BioGPT / ChemDFM:用自定义贪心解码循环替代通用 generate(),配合 KV Cache 管理与 ACL 高性能算子策略,实现 10%~15% 的端到端加速。
• GROVER:引入 SDPA 融合注意力并扩展预热覆盖序列长度,消除尾部延迟毛刺,实现 10.5% 的 P50 加速。
04
开发者行动:
在河套,共筑AI生态未来
目前自动适配工具SLAI-AscendBridge已开源;自动提速优化工具KernelCAT已开启内测,以申请制形式开放试用,欢迎开发者、科研机构与产业伙伴共同完善国产算力的模型交付与性能工程能力。
● 开源项目(AscendBridge|自动适配):https://gitcode.com/AI4Science/SLAI-AscendBridge(点击“阅读原文”即可跳转)
沉淀“人 + AI”深度适配经验,聚焦科学计算与前沿标杆模型的高质量交付。
https://chongweiliu.github.io/slai-ascend-auto-adapt/dashboard/
实时展示通过多智能体协作实现的 500+ 模型全自动适配成果与运行状态。
● 性能优化能力(KernelCat|自动提速):当前以内测API形式开放,面向合作伙伴提供接入与联合优化支持(欢迎申请内测)。

