
SLAI Seminar】第十八期回顾 | 从数据特征理解深度学习:频率原则、凝聚现象与推理偏好
SLAI Seminar
2025年12月29日(周一)上午,SLAI 第18期 Seminar 系列活动顺利举办。本次讲座主持人为王东教授,特邀上海交通大学许志钦教授作题为“从数据特征理解深度学习”的学术报告,围绕深度学习一系列关键现象展开系统梳理,包括频率原则(从低频到高频的学习偏好)、参数/神经元凝聚现象、以及初始化与“记忆—推理”行为之间的关系等。

讲座简介
本次报告围绕“从数据特征理解深度学习”展开,系统梳理了深度网络在学习与泛化中的若干关键现象与机制:从频率视角揭示神经网络“低频先学、高频后学”的频率原则,并由此解释振荡函数拟合与多尺度结构设计;从有效复杂度出发介绍同层神经元的参数凝聚现象,说明过参数化网络表面复杂但有效自由度可能更低;进一步聚焦大模型中的“记忆—推理”权衡,提出初始化尺度超参数(伽马)可作为影响模型偏好记忆或推理的“基因”,并以组合泛化、扩散模型控制与语言建模实验展示其实际效果;最后从数据统计结构角度分析语义关系如何通过不同阶统计量驱动嵌入形成,连接“数据—模型—优化”三者,为理解与改进大模型训练提供可操作的视角。

讲座内容
报告以多个直观问题切入,讨论“过参数化为何未必带来严重过拟合”“神经网络在无数据区域会如何插值”等核心困惑,并指出研究深度学习需要同时关注模型、数据与优化三者的耦合。许教授首先从频率角度解释神经网络训练中“先学到模糊轮廓、再学习细节”的现象,提出模型对低频结构具有天然偏好,由此也能理解为何在缺少中间数据点时,网络往往更倾向于学习平滑解而非高频振荡解;相关认识还可反向指导多尺度网络结构设计,更有效捕捉细节与高频信息。

随后,许教授从“有效复杂度”的视角介绍了 ReLU 网络的凝聚现象:虽然网络表面参数量很大,但训练过程中同层神经元可能沿相似方向生长并趋同,从而使“有效神经元数”显著小于名义规模。通过拟合示例展示了网络如何在训练中逐步“长出”新的转折点以提升表达能力,并进一步讨论凝聚现象与初始化尺度、训练动力学之间的关系,给出过参数化网络不显著过拟合的一种解释路径:模型最终实际使用的有效自由度可能远低于表观规模。

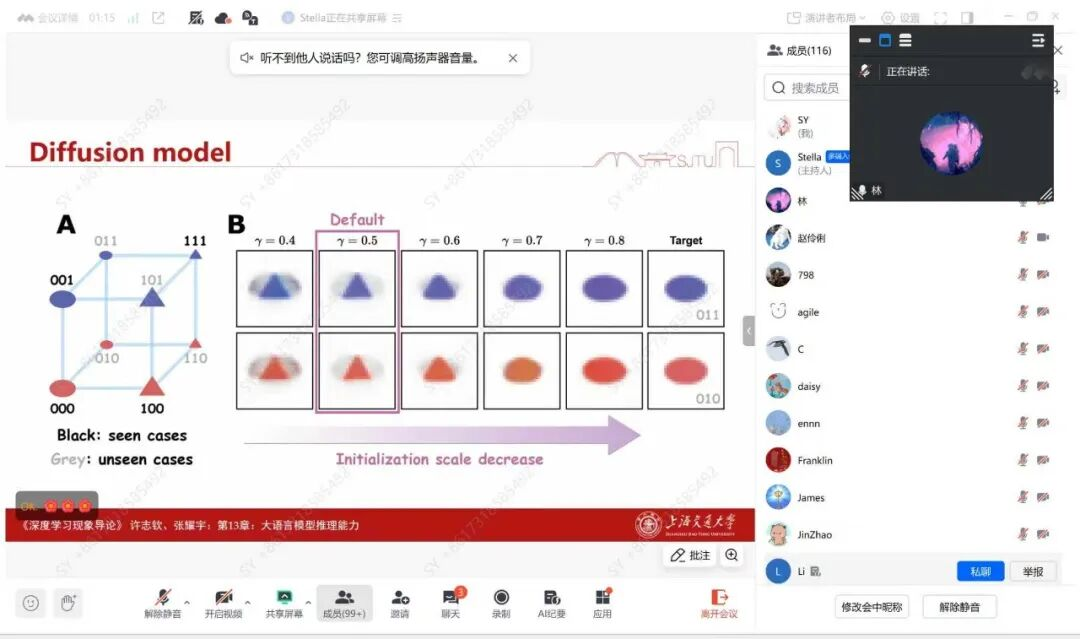
紧接着更具互动性的环节,许教授用一个“背表格—找规律”的简化任务类比大模型的记忆与推理,并提出以初始化超参数γ\gammaγ(控制参数初始尺度)作为关键“基因”来刻画模型偏好:当 γ\gammaγ 变化时,模型在同一任务上可能呈现从“见过才会”的记忆型行为,逐步过渡到能利用函数关系、对称性乃至基元规则的推理型行为。报告进一步将这一理解迁移到扩散模型的组合泛化失败案例中,展示通过调整初始化超参数即可显著改善未见组合条件下的生成效果,并指出初始化在大模型训练中仍是敏感且常被忽视的重要因素。
讲座现场、线上参与氛围踊跃,参与人数近两百人。问答环节讨论十分热烈,与会师生围绕凝聚现象与优化器/归一化方法的关系、初始化大小与训练速度的权衡、推理能力的不同层次(单步推理与链式思维推理)以及“统计结构如何驱动词向量嵌入学习”等问题展开深入交流。

讲座最后在热烈掌声中圆满结束,报告所涉及的多角度数据刻画方法为理解深度学习的泛化、表示与推理提供了清晰线索,也为大模型训练与结构设计带来有启发的实践指导。

