

SLAI基于国产算力集群完成DeepSeek-V4-Pro全参数后训练

导读
当今人工智能时代,基于国产算力的大模型高效训练和推理是国家发展战略的大问题。DeepSeek-V4-Pro在效率和性能方面是业界大模型的杰出代表。DeepSeek-V4-Pro已经成功完成在国产算力上推理部署,但训练还未完全实现国产算力化。
在此背景下,深圳河套学院Al训练平台项目团队,联合哈尔滨工业大学(深圳)、深圳大数据研究院、华为GTS(全球技术服务)、计算产品线、2012实验室,协同深智城AI算力平台,面向国产算力大模型训练开展联合攻关。目前,仅用1个月时间,项目已基于昇腾910C国产算力集群实现DeepSeek-V4-Pro全参数续训练/SFT稳定运行,完成长稳训练1500+步,训练MFU超30%,关键训练算子效率提升14%。
据公开资料检索,本工作是公开可查范围内,业界首个由第三方机构基于国产算力集群完成的DeepSeek-V4-Pro全参数后训练工程实践,标志着国产AI基础设施正在从推理部署和轻量化微调迈向超大模型全参数后训练。
01 为什么万亿级模型的“全参数后训练”是一块硬骨头?
DeepSeek-V4-Pro,一款1.6万亿参数级MoE开源旗舰模型,采用了CSA+HCA混合稀疏注意力、mHC连接等新机制。相比于上一代DeepSeek-V3/R1,它对国产训练框架提出了全方位的“极限挑战”。
稀疏MoE结构:专家路由带来的跨节点通信,是传统密集模型的数十倍;
混合稀疏注意力:注意力模式的动态切换,对算子效率和显存管理极为敏感;
万亿参数级状态:权重、梯度、激活、优化器状态——仅单副本就需数TB显存。
02 核心进展:千卡集群上,1500+步稳定奔跑
经过联合攻关,项目已基于千卡级昇腾 910C 国产算力集群,成功实现DeepSeek-V4-Pro在国产算力集群上的全参数后训练稳定运行。
长稳SFT训练:完成1500+步迭代,skipped iterations = 0,NaN iterations = 0;
训练效率:MFU(模型算力利用率)达到约30%,关键训练算子计算效率较初始版本提升约14%;
最终表现:在昇腾超节点上,MFU稳定在34.9%。
与此同时,DeepSeek-V4-Flash的全参数续训练与SFT链路也已同步打通。
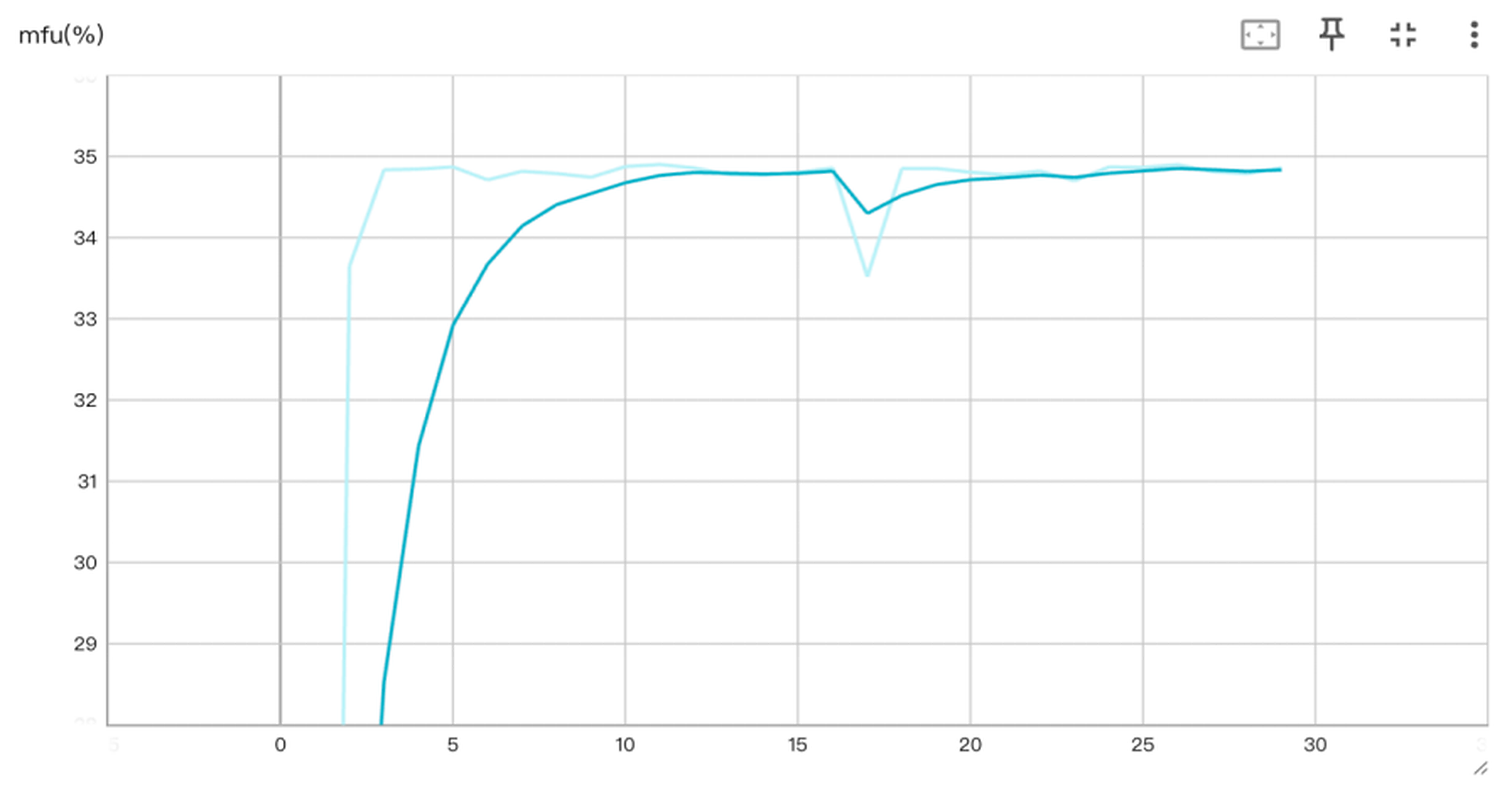
DeepSeek-V4-Pro@昇腾超节点训练,MFU最终稳定在34.9%
一组数据足以说明差距:在同等参数量下,业界公开的国产算力全参数后训练案例几乎为零。而我们将一个1.6T MoE模型,在千卡集群上以27秒/步的稳定节奏,连续奔跑1500余步——这不是实验室的“单次演示”,而是可复现、可工程化交付的稳定能力。
更重要的是,该平台已快速验证了垂直领域价值。团队围绕工业级自动化运筹建模场景,在数周内完成了从数据生产、样本筛选、训练链路打通到效果评测的闭环验证。这意味着:国产算力平台不仅能够“训大模型”,更能“训好行业模型”——以短周期、低成本构建面向专业任务的增强能力。
03 三大关键技术突破:从“能跑”到“能训、训稳、训优”
本次攻关面向DeepSeek-V4-Pro全参数后训练,而非LoRA等少量参数微调。联合团队在以下三个层面实现了系统性突破:
1. 分布式承载:1.6T参数的“显存拼图”
洞察: 万亿参数不能只靠显存大,更要靠“放得巧”。
项目成功构建了权重、梯度、激活、优化器状态的分布式承载方案,使得数据并行、张量并行、流水并行与专家并行四者协同工作。每一张卡上,该放什么、怎么放、如何动态调度——这套“显存拼图”是稳定训练的地基。
2. 稀疏与通信:让专家不“吵架”,让注意力不“堵车”
洞察: MoE模型训练最怕“专家负载失衡”和“跨节点通信风暴”。
团队针对混合稀疏注意力、MoE路由、归一化、矩阵计算等关键训练算子进行了深度适配与优化,算子效率较初始版本提升14%。同时建立了专家负载的实时监控与均衡机制,避免部分专家过载而部分专家闲置。
3. 长稳监控:当训练跑上几天几夜,谁来守夜?
洞察: 全参数后训练最可怕的不是慢,而是“跑着跑着就崩了”。
联合团队搭建了一套完整的监控体系:Loss曲线、梯度范数、专家负载、显存占用、异常自动恢复……所有指标均可视、可告警、可自愈。在1500+步的训练中,未出现一次Loss失控或NaN值——这是“长稳能力”最直接的证明。
04 实战验证:数学建模能力在后训练中显著跃升
为了检验DeepSeek-V4在昇腾集群上进行全参数后训练的真实价值,项目设计了一项“硬核”实验:增强大模型的数学建模能力。
团队搭建了一条SFT建模数据生产workflow,产出3000条高质量数学建模任务SFT样本,覆盖4类目标任务和3种问题形态。随后,对DeepSeek-V4进行后训练。
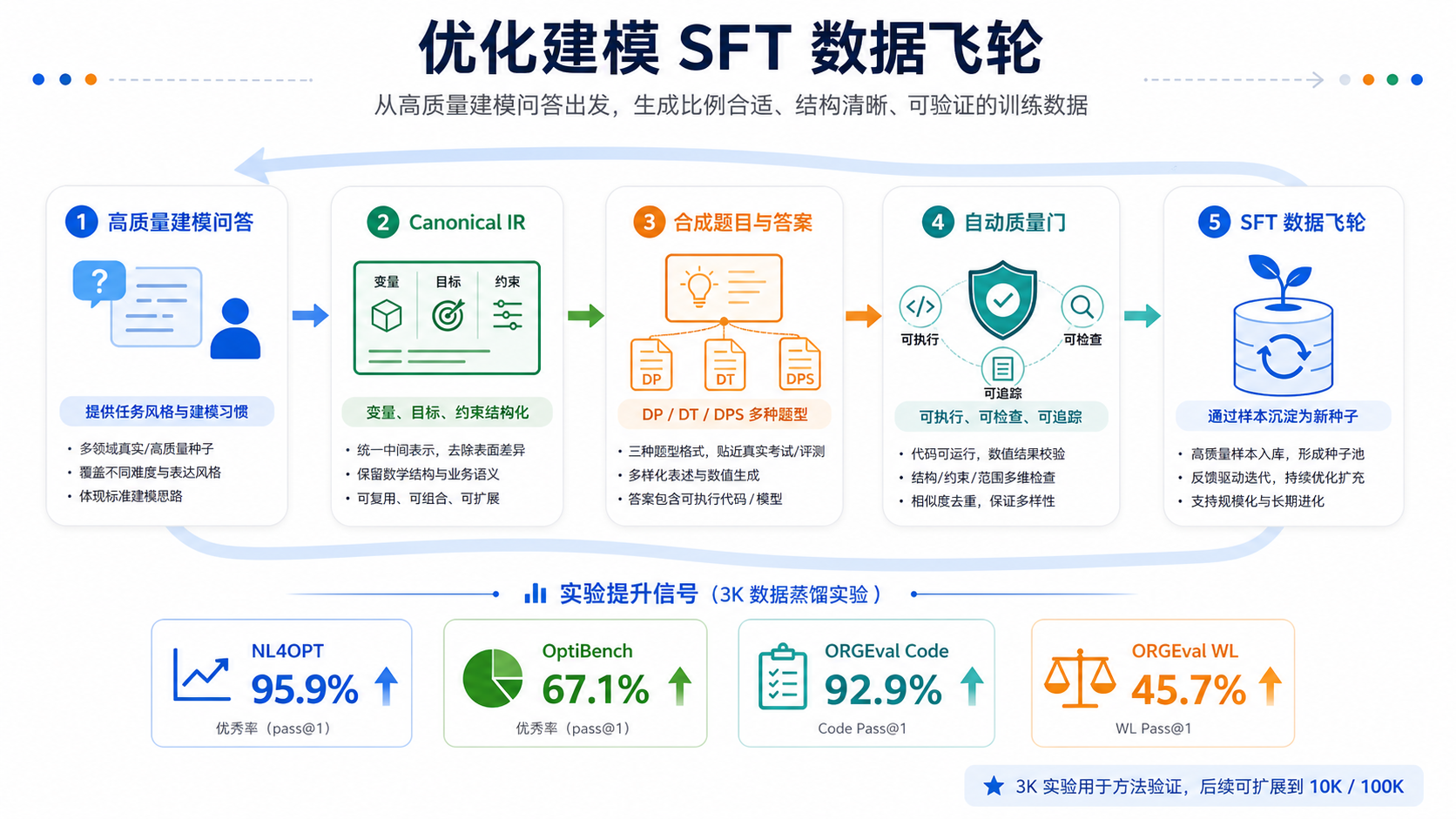
优化建模SFT数据飞轮流程
训练曲线给出了清晰的信号:
LM loss从高位快速下降,最终收敛至0.2056;
MTP-1 loss收敛至0.2538;
梯度范数平稳下降,未出现震荡或发散;
单步耗时稳定在27秒左右。
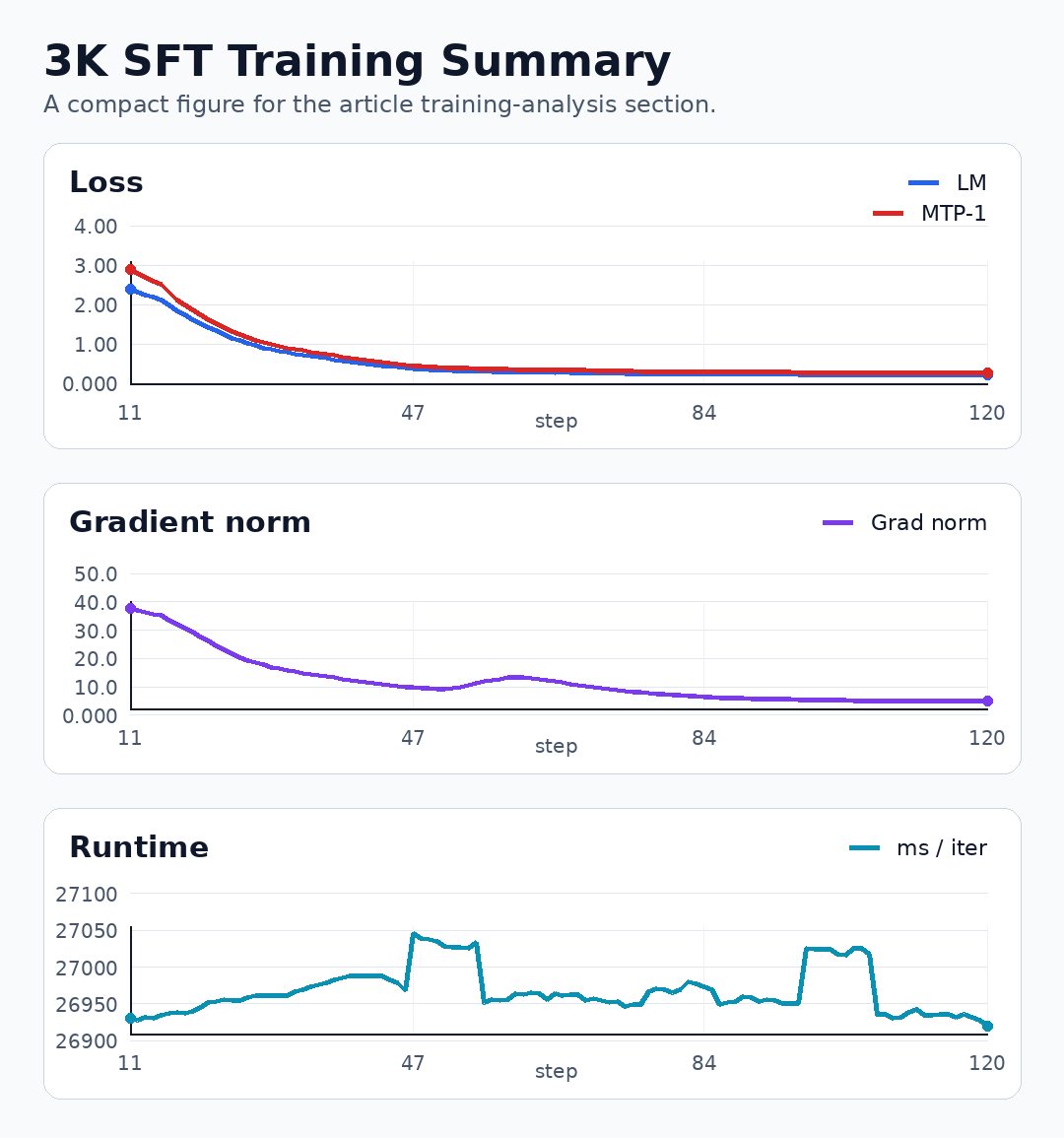
3K SFT训练过程概览
更直观的结果来自Benchmark对比:
| 指标 | 微调前 | 微调后 |
| NL4OPT | 93.1% | 95.9% |
| OptiBench | 65.5% | 67.1% |
| ORGEval Code | 90.1% | 92.9% |
| ORGEval WL | 40.6% | 45.7% |
四项关键指标均显著超越原模型,其中ORGEval WL提升超过5个百分点。这意味着:在国产算力上完成的全参数后训练,不仅能“跑稳”,更能“训强”——模型在复杂推理任务上的能力得到了真实增益。
05 以战育才:在真实攻关中培养“能训大模型”的人
本次攻关的另一个独特价值,在于它是一次人才培养模式的范式实验。
深圳河套学院将万亿级模型训练攻关作为“练兵场”,把学生直接嵌入国产算力真实训练场景。截至目前,项目已培养学生42名,形成了由青年教师指导、博士生核心攻坚、工程团队支撑的协同培养机制。
在这一过程中,同学们不只是参与项目进展,更是承担具体任务的“战斗员”:有的负责训练数据构造与样本质量分析,有的负责分布式并行策略验证,有的跟进长稳监控与异常恢复,有的撰写技术报告与工程文档。
一次训练启动、一次报错定位、一次参数调整、一次结果复盘——在这些真实而琐碎的工程实践中,学生们从“会调用大模型”真正走向了“理解并参与训练大模型”。
能力提升体现在三个方面:
建立了对国产算力大模型训练全链路的系统性认识;
掌握了从领域数据到模型能力增强的全过程实操能力;
在真实项目中形成了问题拆解、实验设计、训练复盘与团队协作的工程素养。
后续,这些真实任务将沉淀为课程案例、实训资源和学生科研项目,将持续支撑深圳河套学院培养“懂模型、懂系统、能工程、敢攻关”的高水平复合型AI人才。
 |  |
 |  |
 | |
项目团队开展技术复盘与学生实战培养
06 未来展望:从“全参数后训练”走向“Agentic RL + 超长上下文”
下一阶段,深圳河套学院将继续联合哈尔滨工业大学(深圳)、深圳大数据研究院、华为GTS(全球技术服务)、计算产品线、2012实验室、深智城等合作伙伴,在现有全参数续训练/SFT链路基础上,重点推进三项任务:
1. 训练效率再突破
持续优化训练框架与关键算子,进一步提升训练效率(MFU),降低万亿模型训练的算力成本。
2. 超长上下文训练
支撑512K至1M超长上下文训练,提升复杂专业任务中的长文档理解与长链路推理能力;
3. 强化学习后训练闭环
突破DeepSeek-V4-Pro强化学习后训练技术,围绕数学建模优化、代码Agent、长上下文推理等任务,构建rollout生成 → 工具执行 → reward/verifier → 策略更新 → 评测反馈的完整Agentic RL链路。
同时,项目将坚定推进技术开源与人才培养沉淀:
分阶段开放训练配置、评测脚本、合成数据、技术报告及相关模型与框架能力;
将真实训练任务、数据构造方法、故障排查案例和评测流程转化为课程案例与实训任务;
持续完善“国产算力支撑、真实任务牵引、学生团队实战、工程能力沉淀”的培养路径。
在此基础上,项目还将依托这一训练场,开展新一代通用人工智能的基础理论、新范式和新架构的研究——包括符号、连接与行为主义有机融合,从单一智能体到群体智能再到人机融合的建模探索。
结语
DeepSeek-V4-Pro在国产算力上的全参数后训练,不是一次孤立的工程突破。
它验证了一条道路:国产开源旗舰模型 + 国产AI算力 + 高水平训练团队 + 国产厂商技术支持——这个四角闭环,是可持续的、可复制的、可信任的。
它发出了一声宣告:国产AI基础设施,从今天起,不再只是“能推理”,而是真正“能训练、能训稳、能训优”。
更重要的是,它点燃了一个希望:在下一代通用人工智能的征途上,中国的高校、科研机构和年轻学子,可以站在自己的算力土壤上,开展人工智能的研究,亲手训练属于自己的万亿模型。
这不是终点,而是发令枪。
项目后续将逐步开源技术报告、训练配置与评测脚本,敬请关注深圳河套学院官方发布。



