

AscendBridge 2.0正式开源:3天→1小时,模型全自动适配与调优工具
2026年4月30日,深圳河套学院联合华为正式开源AscendBridge 2.0。该工具适配Hugging Face的模型迁移至昇腾NPU的推理适配与性能优化场景,通过多智能体协同机制,将模型获取、代码适配、错误自愈、精度对齐、性能调优和业务验收串联为自动化流程。
在已完成的验证中,AscendBridge 2.0覆盖了321个主流模型、142个发布方/组织、30余个真实业务数据集以及13类质量指标。典型场景下,单模型适配周期可由原来的天级缩短至小时级,为昇腾AI生态中的模型规模化迁移提供了工程化工具支撑。
作为该工具的研发主体,深圳河套学院始终聚焦培育顶尖人工智能领军人才,推动人工智能关键领域理论创新与应用突破。围绕该项目,学院汇聚了数十位骨干教师与博士持续攻关,并联动华为、深圳市大数据研究院、智子芯元等伙伴协同研发,目前已取得显著进展。
工具核心能力:适配调优全流程自动闭环
AscendBridge 2.0垂直聚焦PyTorch框架的模型适配至昇腾NPU的推理场景,在适配与调优的路径上做深做透,实现工程化落地。通过6大智能体协同,工具复刻专业工程师团队全流程工作流,完成模型爬取、代码适配、错误自愈、精度对齐、性能调优、业务对比验收的全闭环。
工具核心架构:6大智能体组建全自动适配与调优流水线
传统模型适配与调优依赖单人全流程包办,任一环节停滞即全线瘫痪,完全依赖个人经验,AscendBridge 2.0构建了标准化工业装配线,实现角色解耦、权责隔离、流程约束。

图1:六大智能体工厂流水线

表1:模型适配与调优自动化产线角色的核心职责
主要工程设计:三把“工程锁”针对性解决适配与调优难题
AscendBridge 2.0用三把“工程锁”,逐一解决了适配与调优过程中最常见的几类痛点——先证伪、再迁移,出问题能回滚。
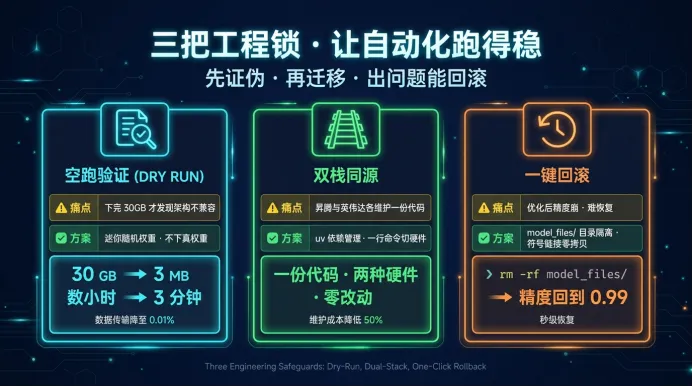
图2:三把工程锁:DRY RUN/双栈同源/一键回滚
1.DRY RUN 空跑验证:先证伪,再适配
痛点:传统适配需先下载数十GB模型权重,有时下载后才发现架构不兼容,前期投入浪费。
解决方案:自动生成迷你版随机权重模型,不下载真实权重,仅验证代码路径和算子兼容性。
效果:模型验证的占用文件规模从30GB压缩至3MB,验证时间从数小时缩短至3分钟。
2.双栈同源:一份代码,两种硬件通吃
痛点:昇腾与其他平台各维护一份代码,长期维护成本高,易出现版本不一致。
解决方案:基于uv依赖管理,一行命令切换硬件环境,代码零改动。
3.模型文件覆盖:优化版可回滚
痛点:性能优化后精度崩盘,无法快速恢复至原始状态。
解决方案:
○所有优化产物集中存入独立的model_files/目录
○ 小文件直接复制,大权重采用符号链接(不重复占用存储空间)
○ 精度异常时,执行rm -rf model_files/即可一键回滚
多维度的精度评估体系
AscendBridge2.0将精度对齐作为模型适配的基本要求和性能优化的前提,建立了分层分类的精度评估机制:

图3:精度对齐+三层优化,DUTIR-BioNLP/Taiyi-LLM提速+37.7%
分类评估:自动将模型输出归为11类,要求模型同输入下NPU与业界基线输出的logits余弦相似度>0.99,部分增加额外的指标检测。
○ BERT类:输出的余弦相似度
○ 大语言模型:输出的余弦相似度+PPL困惑度
○ 检测模型:输出的余弦相似度+IoU交并比
○ ASR语音识别:输出的余弦相似度+WER词错误率
根因自动诊断:沉淀6大类精度不对齐根因,绑定独立诊断工具链。
硬件数值差异、dtype精度敏感、算子回退CPU、融合算子语义错位、随机采样差异、权重/评测口径不一致。
多层推理优化架构,实测DUTIR-BioNLP/Taiyi-LLM提速37.7%
1.多层优化体系
通过已落地的3大优化技术实现推理性能显著提升,分别为换算子、计算图优化、算子下发队列优化。

图4:已落地的三大技术:换算子、计算图优化、算子下发队列优化
其他优化手段包括精度量化加速、推理框架与算子生成等,目前仍在持续探索与验证中。
智能体完全理解昇腾算子的各个方面,快速适配各类算子替换,消除算子替换过程中的问题,其中如下四个融合算子的修改经常能带来收益:
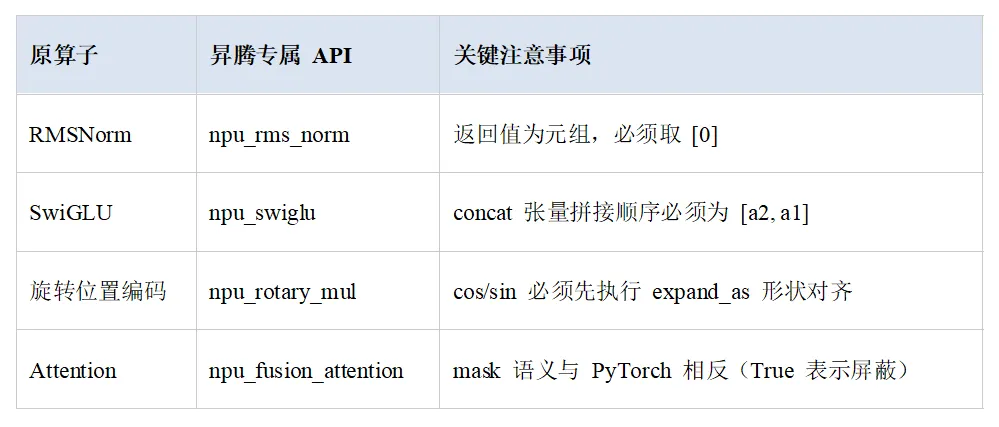
表2:四个融合算子的相关介绍
2.实测效果与通用加速技巧
DUTIR-BioNLP/Taiyi-LLM:将以上表2中的四个算子全量替换后,推理速度提升37.7%,logits余弦相似度保持>0.99。
通用加速技巧:智能体能自动发现通用算子下发队列优化技术,经过证明是一个能够有效泛化到各种模型加速的技术。
3.“精度优先”的案例
工具文档明确记录了Qwen3-Embedding模型的案例:启用npu_fusion_attention后,embedding余弦相似度从0.99跌至0.94,根因为bf16精度下attention mask数值交互放大误差。最终处置方案为回退至原生PyTorch实现,精度恢复至0.99,体现了“精度优先”的工程原则。
工程化质量保障机制
1.主要保障机制
Self-Healing自愈:适配阶段报错时,智能体自动读取日志、定位根因、修改代码并重跑。
uv环境隔离:每个模型拥有独立虚拟环境,彻底避免依赖冲突。
Completed Gate完成门禁:任何阶段必须通过校验脚本,累计100+条校验规则。
Skill库+持久记忆:将所有踩过的坑、优化方案沉淀为共享技能库,实现经验复用。
2.关键校验规则(对冲大模型幻觉)
精度与性能评测样本量≥50个。
加速比以整轮挂钟时间为准,禁止使用单次延迟反推。
报告中出现“cold baseline” “partial run”等字样直接判定无效。
NPU与业界评测保持数据集、batch size、dtype、样本顺序基本一致。
提速≥3倍时必须提供独立基线、稳态延迟证据和验证说明。
开源成果与适用角色
1.开源清单
AscendBridge2.0工具源代码:完整的端到端自动化适配与调优产线(6个智能体、 3把工程锁、优化方法论、100+校验规则)。
321个模型适配脚本:已在昇腾A3设备完成完整测评,并与业界竞品同口径精度/性能对比。
○ 覆盖142个发布方/组织、30+真实业务数据集、13种质量指标
○ 前十大模型类:BERT/Transformer编码器(56)、音频/语音(29)、Qwen系列(28)、视觉模型(17)等
○覆盖主流厂商:Alibaba、Meta、Microsoft、Google、IBM、OpenAI等
○ 覆盖AI4S场景模型73个:包含生物医学与临床NLP、蛋白质与基因组计算、材料科学与分子预测、空间与地球科学等分类
2.适用对象
国产化适配工程师:可直接找目标模型或同族模型的适配脚本,单模型适配从天级压缩至小时级。
AI Agent工程化团队:可作为Agent系统的参考,学习权责隔离、状态机门禁、自愈机制等设计。
私有化部署团队:将3人/天的工作量压缩至数小时,仅需完成最后一步人工核验。
3.开源地址
主仓库:
https://gitcode.com/SLAI/SLAI-AscendBridge2
适配模型仓库:
https://gitcode.com/SLAI/SLAI-AscendBridge2-Adaptations
自2026年2月AscendBridge1.0开源以来,该工具已成功支撑深圳河套学院在脑机接口、具身智能等科研场景中的模型适配,并在AI4S科研、文旅、制造、金融等多个领域实现落地应用。本次开源的2.0版本实现了能力的全面升级,将进一步覆盖更广领域、沉淀更多应用实践。
面向未来,深圳河套学院将持续深化AscendBridge的自动化与智能化能力,进一步拓展模型库与业务场景边界,探索错误自愈、算子自动生成等方向的自我进化机制,同时联动华为等生态伙伴,推动昇腾AI生态从“可迁移”迈向“易迁移、自优化”的新阶段,为全球开发者提供更高效、更智能的国产算力迁移基础设施。



